Transductive Visual Programming:
Evolving Tool Libraries from Experience for Spatial Reasoning
Shengguang Wu1, Xiaohan Wang1, Yuhui Zhang1, Hao Zhu1, Serena Yeung-Levy1
1Stanford University
Abstract
Spatial reasoning in 3D scenes requires precise geometric calculations that challenge vision-language models. Visual programming addresses this by decomposing problems into steps calling specialized tools, yet existing methods rely on either fixed toolsets or speculative tool induction before solving problems, resulting in suboptimal programs and poor utilization of induced tools. We present Transductive Visual Programming (TVP), a novel framework that builds new tools from its own experience rather than speculation. TVP first solves problems using basic tools while accumulating experiential solutions into an Example Library, then abstracts recurring patterns from these programs into reusable higher-level tools for an evolving Tool Library. This allows TVP to tackle new problems with increasingly powerful tools learned from experience. On Omni3D-Bench, TVP achieves state-of-the-art performance, outperforming GPT-4o by 22% and the previous best visual programming system by 11%. Our transductively learned tools are used 5× more frequently as core program dependency than inductively created ones, demonstrating more effective tool discovery and reuse. The evolved tools also show strong generalization to unseen spatial tasks, achieving superior performance on benchmarks from SpatialScore-Hard collection without any testset-specific modification. Our work establishes experience-driven transductive tool creation as a powerful paradigm for building self-evolving visual programming agents that effectively tackle challenging spatial reasoning tasks.
Method: TVP's Dual-Library Architecture
TVP implements a closed-loop paradigm via two interconnected libraries: an Example Library that accumulates program solutions as experience, and a Tool Library that maintains functions abstracted from these programs. The dual-libraries enable the circular program-tool-program cycle: solving problems generates experience, experience guides tool creation, and newly created tools improve future problem-solving.
Figure: TVP's dual-library architecture. (Phase I) Problem-solving and experience accumulation: For each query, TVP retrieves similar examples from the Example Library and generates programs using the current Tool Library; high-quality solutions join the Example Library. (Phase II) Tool abstraction: Accumulated examples are clustered, and common patterns are abstracted into new tools, which, if passed validation, are added to the Tool Library for future use. Click to play the animation.
Results on Omni3D-Bench
| Method | Yes/No | Multiple Choice | Counting | Float MRA | Float (±10%) | Overall (%) |
|---|---|---|---|---|---|---|
| Generic VLMs | ||||||
| GPT-4o | 65.3 | 60.5 | 18.6 | 26.7 | 8.2 | 27.2 |
| Qwen2-VL-7B-Inst | 58.7 | 33.7 | 12.9 | 21.5 | 10.0 | 21.8 |
| LLaVA-OV-7B-Chat | 60.0 | 27.9 | 22.9 | 26.8 | 11.1 | 23.0 |
| Molmo-7B-D | 46.7 | 41.9 | 18.6 | 28.4 | 8.9 | 21.6 |
| Spatial-Finetuned VLMs | ||||||
| SpaceMantis | 53.3 | 30.2 | 4.3 | 21.4 | 8.2 | 18.2 |
| SpatialBot-3B | 60.0 | 30.2 | 0.0 | 17.7 | 8.5 | 18.8 |
| Visual Programming | ||||||
| VisProg | 54.7 | 25.9 | 2.9 | 0.9 | - | - |
| ViperGPT | 56.0 | 42.4 | 20.0 | 15.4 | - | - |
| VADAR | 56.0 | 57.6 | 21.7 | 35.5 | 15.9 | 29.9 |
| TVP (Full System) | 60.0 | 61.6 | 24.3 | 36.5 | 19.3 | 33.3 |
| TVP (Example-Lib-Only, w/o Tool Lib) | 60.0 | 61.6 | 21.4 | 35.5 | 17.0 | 31.7 |
Best in bold, second best underlined. Performance on Omni3D-Bench across different question types.
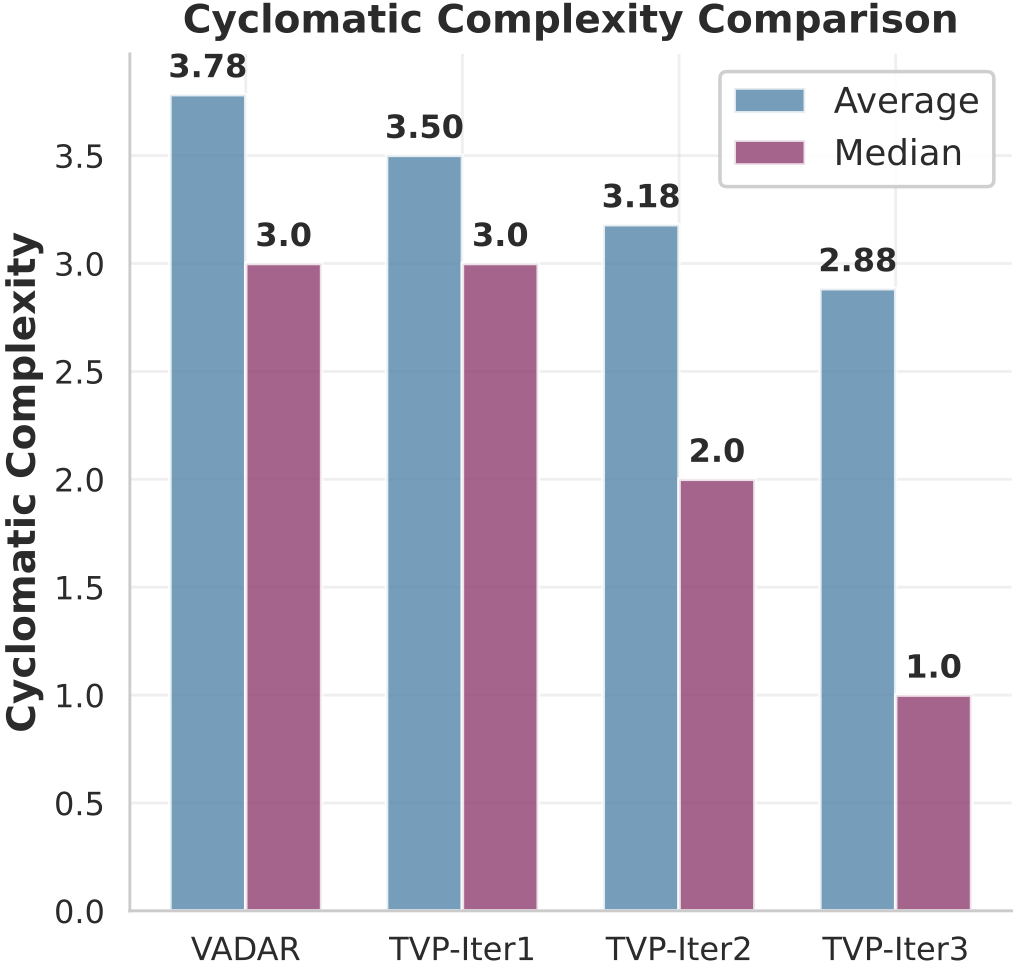
(a) CNN reduction as abstracted tools replace multi-step patterns.
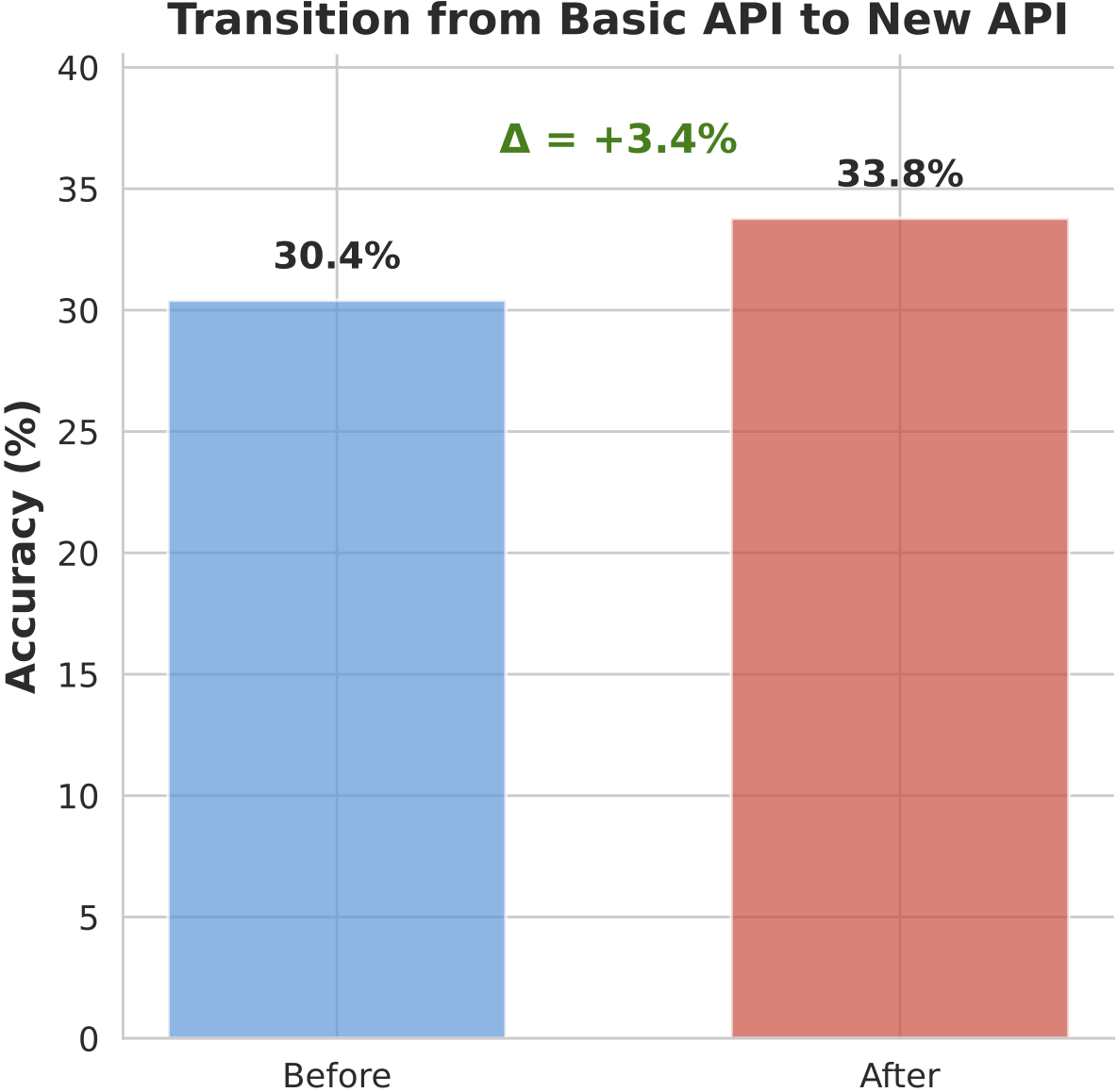
(b) Accuracy gains +3.4% when switching from basic tools to abstracted tools.
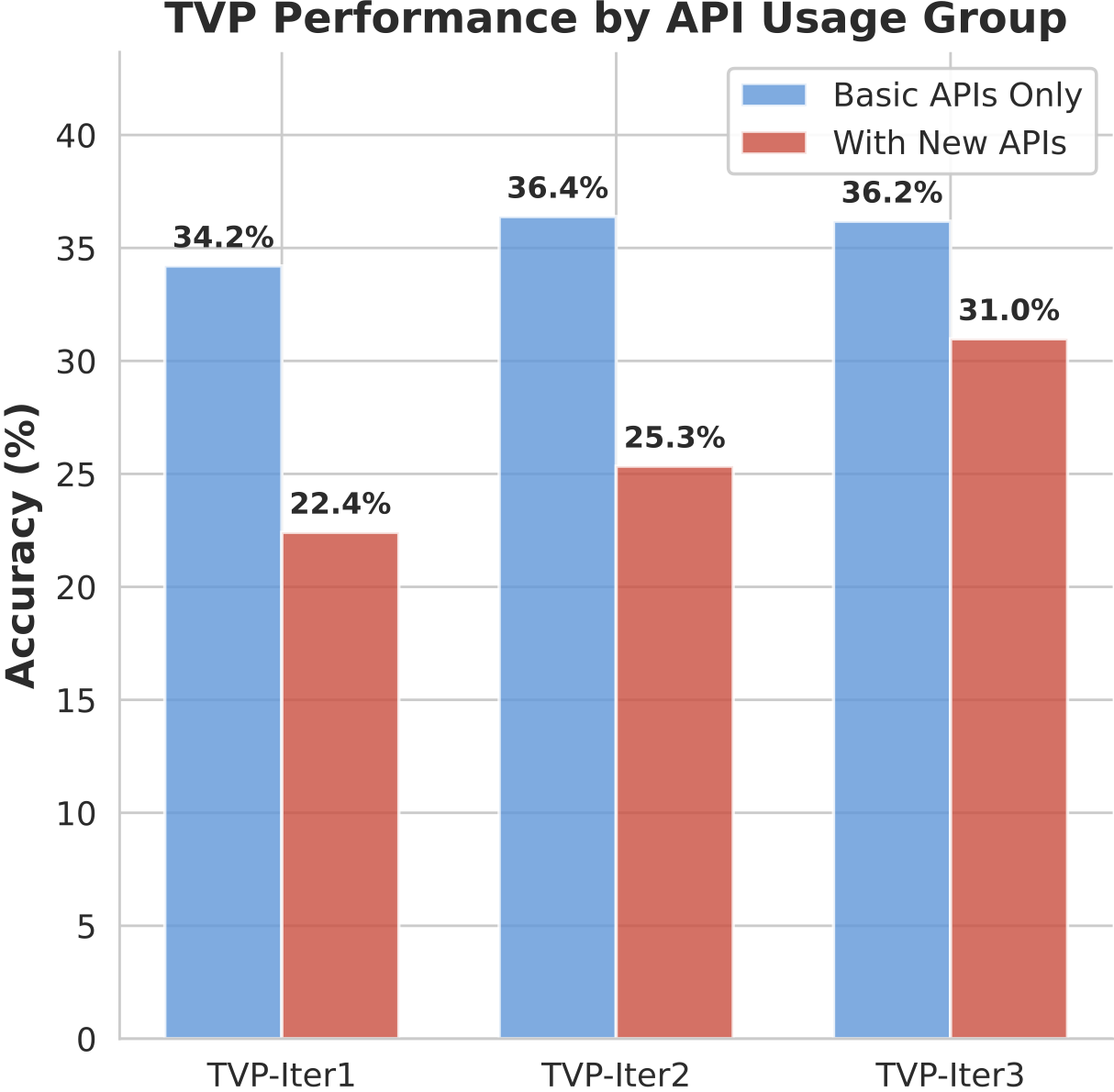
(c) Iterative improvement (+38%) with abstracted tools (22.4% → 31.0%).
Figure: TVP's closed-loop learning produces three measurable benefits. These improvements stem from experience-grounded tool creation: each abstracted function encapsulates recurring high-quality program solutions and passes rigorous validation.
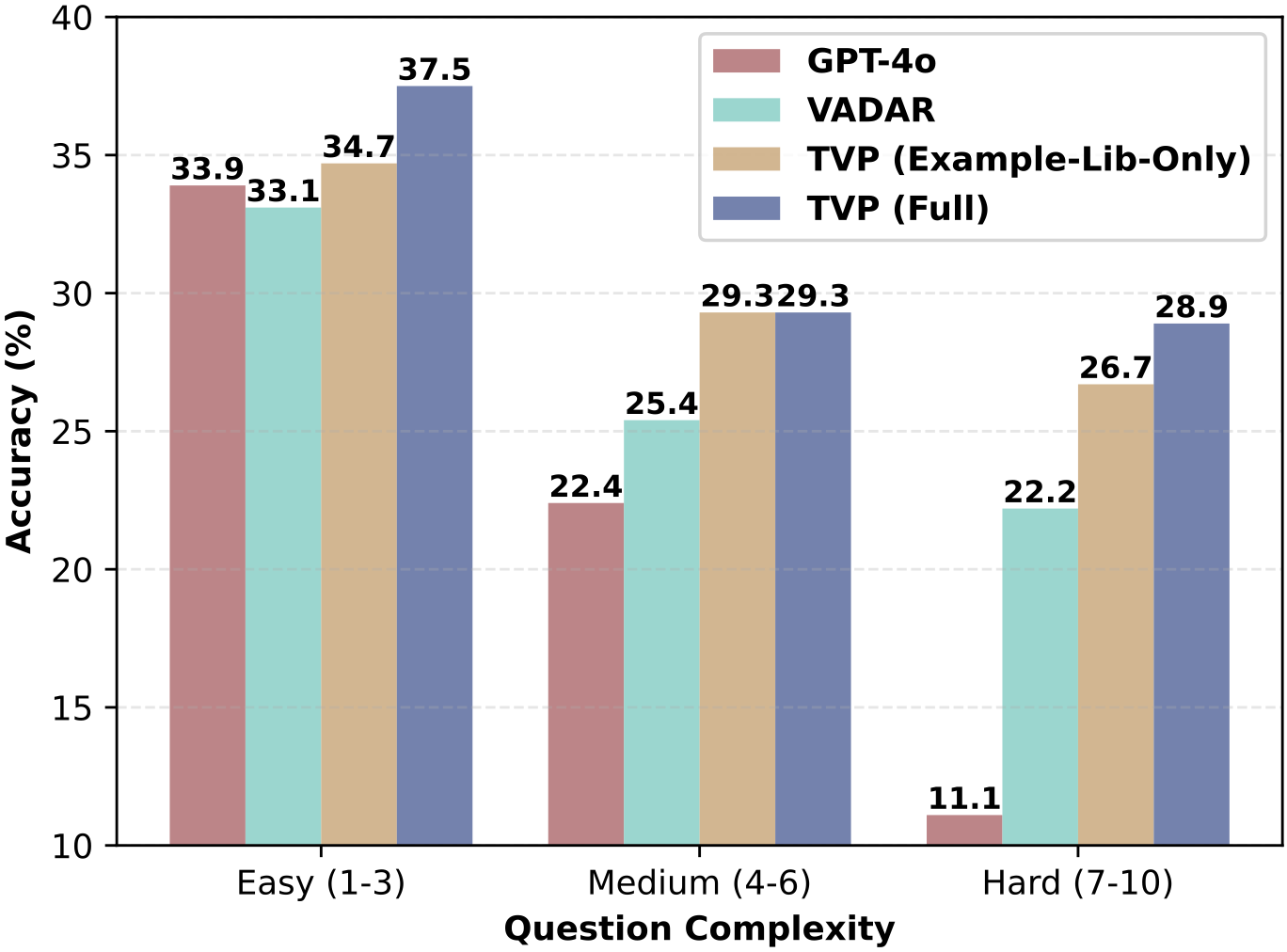
Figure: Performance comparison across question complexity levels (Easy, Medium, Hard). TVP-full-system delivers the best performance on both Easy and Hard batches.

Figure: Performance delta between TVP (Full) and TVP (Example-Lib-Only) across iterations for each complexity level. The hardest questions show the largest improvement (+6.7% by iteration 3) enabled by active tool creation.
Key Insight: For easy questions, thoroughly validated created tools avoid potential reimplementation errors, leading to more stable performance. For harder questions, created tools provide simpler solution steps that eliminate complicated logic, thus easing the program reasoning.
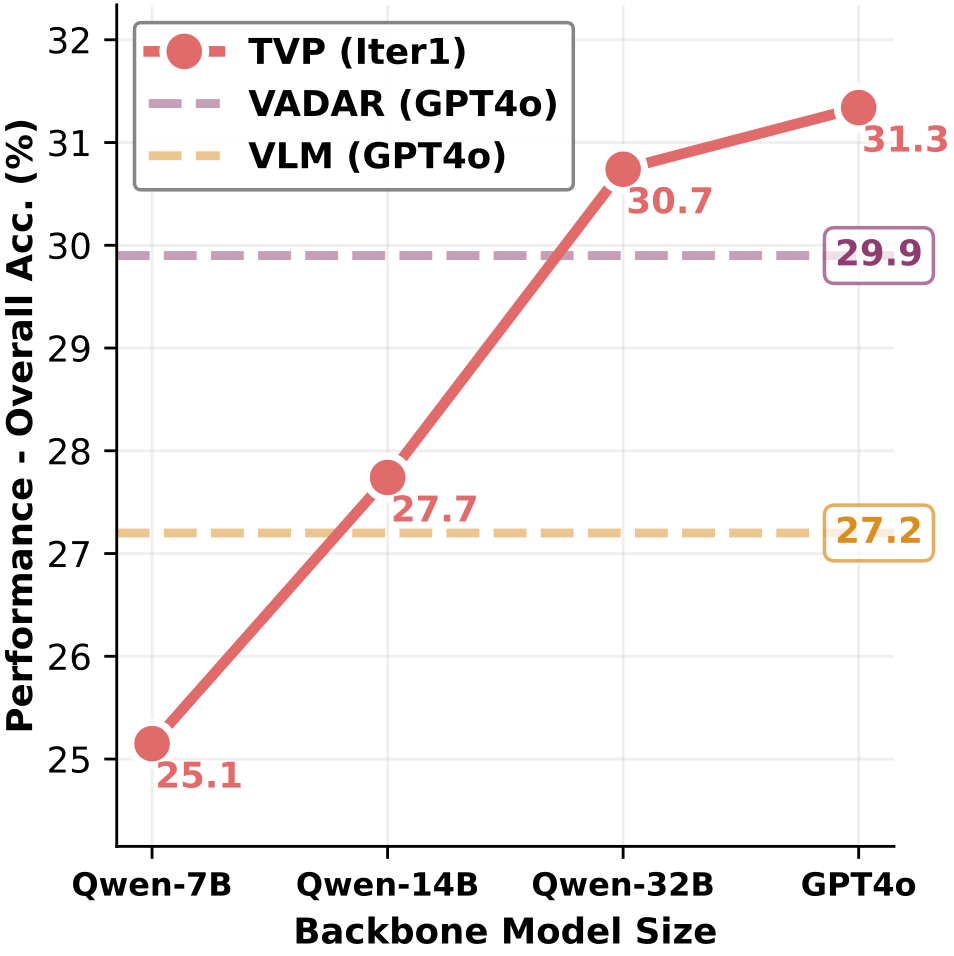
Figure: TVP performance scales consistently with backbone model capacity.
Scaling Behavior
Using the Qwen2.5-Coder-Instruct family (7B → 14B → 32B), TVP exhibits clear performance improvement with increasing model capacity. TVP's architecture is model-agnostic and holds future potential as foundation models improve.
Practical Implication
TVP does not rely on proprietary-specific optimal LLMs but can achieve strong performance with more accessible open-source alternatives, making this transductive tool creation paradigm highly accessible for research and deployment.
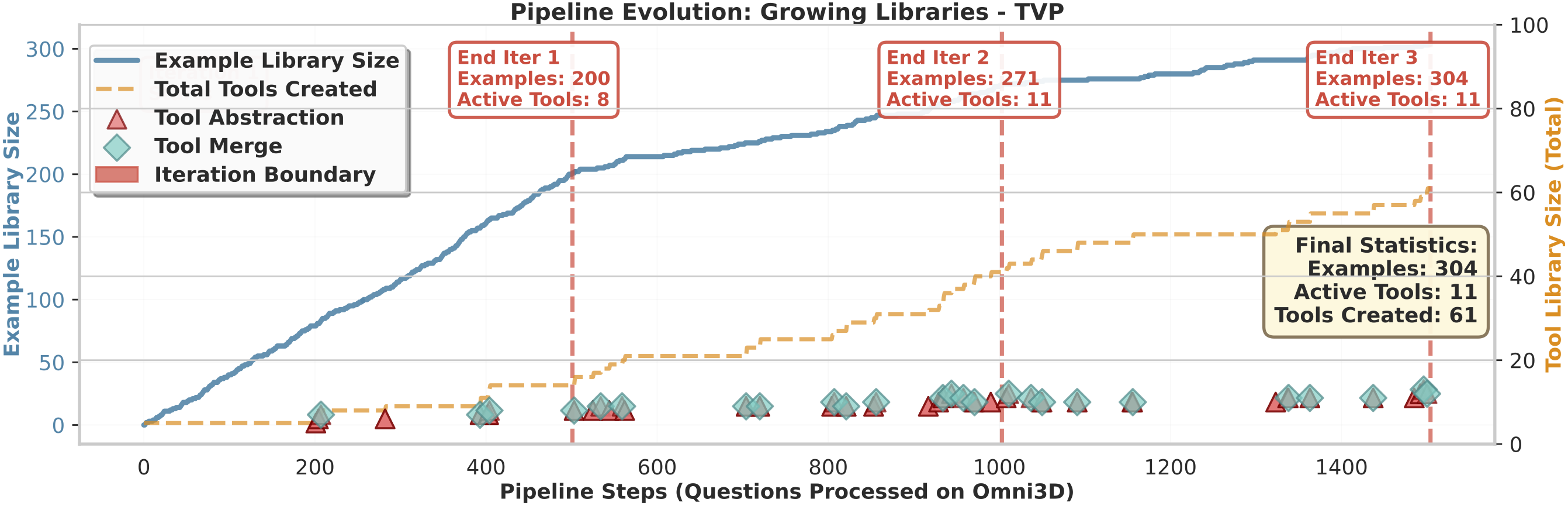
Figure: Evolution trajectory of TVP's dual libraries. The Example Library grows steadily to 304 solutions while the Tool Library expands with controlled maintenance.
Example Library
Grows from 0 to 304 high-quality solutions, accumulating concrete problem-solving experience that grounds tool abstraction.
Tool Library
61 tools created total, 11 remain active after periodic merging to reduce redundancy and improve tool selection.
Key Insight
Selective retention ensures a manageable Tool Library capturing genuinely reusable abstractions with minimal redundancy.
Generalizing To Unseen Spatial Reasoning Queries
Through TVP's transductive paradigm, tools abstracted from experience on one benchmark should capture fundamental reasoning patterns that generalize to new questions. As shown below, TVP's dual libraries, built only on Omni3D-Bench, transfer to unseen spatial reasoning queries from SpatialScore-Hard collection without any modification.
Results on Sampled SpatialScore-Hard Collection
| Method | 3DSR-Bench | SpatialSense | VG-Bench | Overall |
|---|---|---|---|---|
| Generic VLMs | ||||
| GPT-4o | 52.1 | 46.5 | 20.3 | 42.6 |
| LLaVA-OV-7B-Chat | 12.4 | 9.9 | 9.4 | 10.9 |
| Qwen2-VL-Inst | 49.6 | 32.4 | 7.8 | 34.4 |
| Molmo-7B-D | 41.3 | 54.9 | 12.5 | 37.9 |
| Spatial-Finetuned VLMs | ||||
| SpaceMantis | 37.2 | 19.7 | 7.8 | 25.0 |
| SpatialBot-3B | 20.7 | 62.0 | 6.2 | 28.5 |
| Visual Programming | ||||
| VADAR | 24.8 | 40.8 | 39.1 | 32.8 |
| TVPGeneralize | 52.9 | 59.2 | 43.8 | 52.3 |
TVP generalizes zero-shot with only libraries built from Omni3D-Bench.
Category-wise Performance
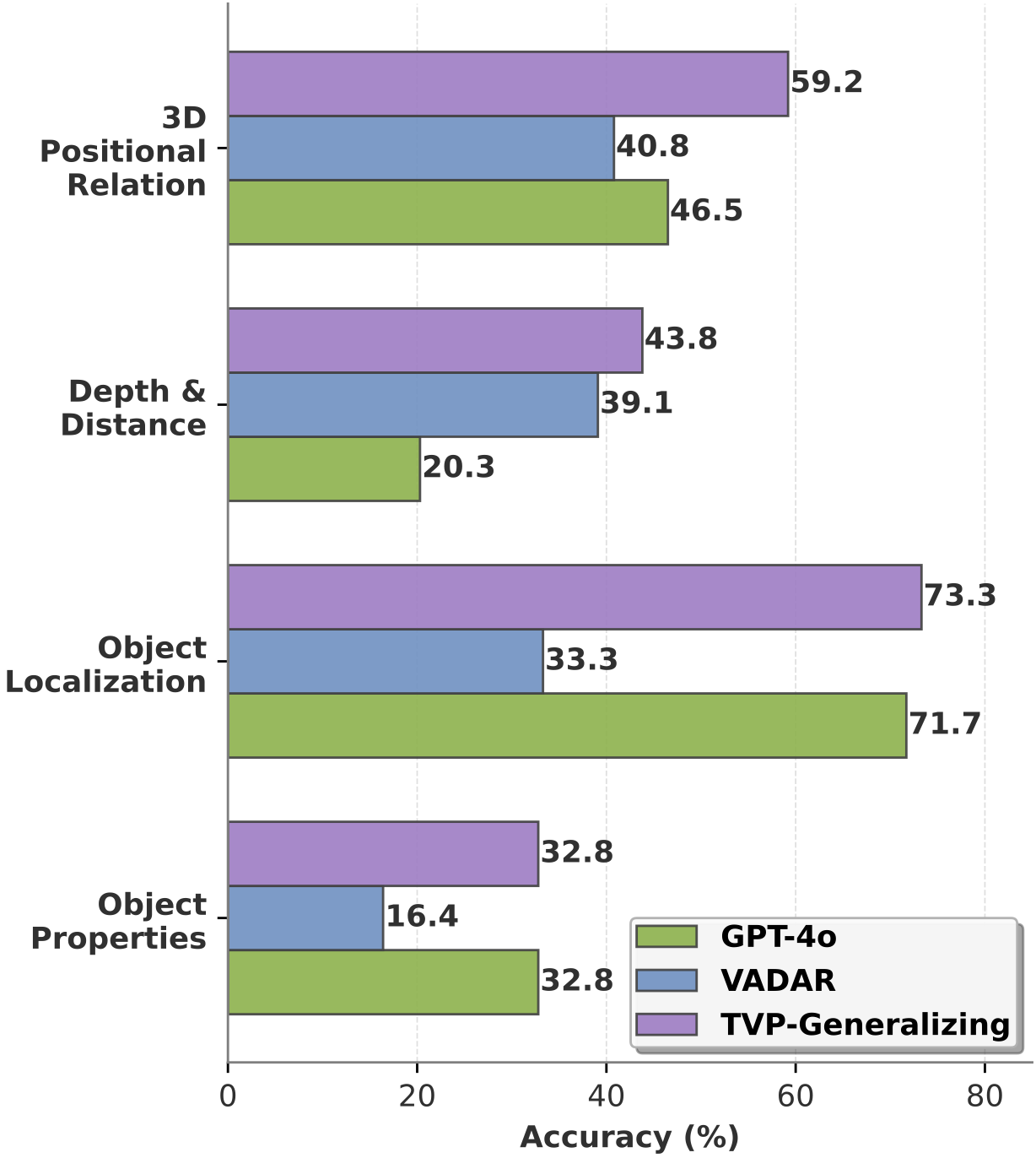
Figure: TVP's libraries transfer well on SpatialScore-Hard, with particular strength on 3D spatial and depth/distance reasoningcategories.
Why Does Transfer Work?
Strong transfer occurs because TVP's transductive tool creation inherently produces general functions through three mechanisms: (1) Tools are abstracted from clusters of similar problems, forcing abstractions to capture shared computational logic; (2) Rigorous validation ensures the abstraction generalizes correctly within its cluster; (3) Tool maintenance merges functionally similar abstractions, leading to more general functions.